
Image generated by Gemini based on the blog post content
https://arxiv.org/pdf/2604.23340
We have all seen Large Language Models (LLMs) write impressive snippets of code or debug a tricky function. AI coding editors like GitHub Copilot are increasingly adopted, with studies suggesting that up to 88% of developers report increased productivity.
But accelerations in development come with trade-offs. Existing studies have shown that LLMs often misuse APIs, introduce security vulnerabilities, and hallucinate. So I got to wonder: Can an LLM actually understand the soul of a complex software project? Can it generate a fully automated, high-quality commit (patch) that satisfies requirements and can be directly incorporated into a major production codebase?
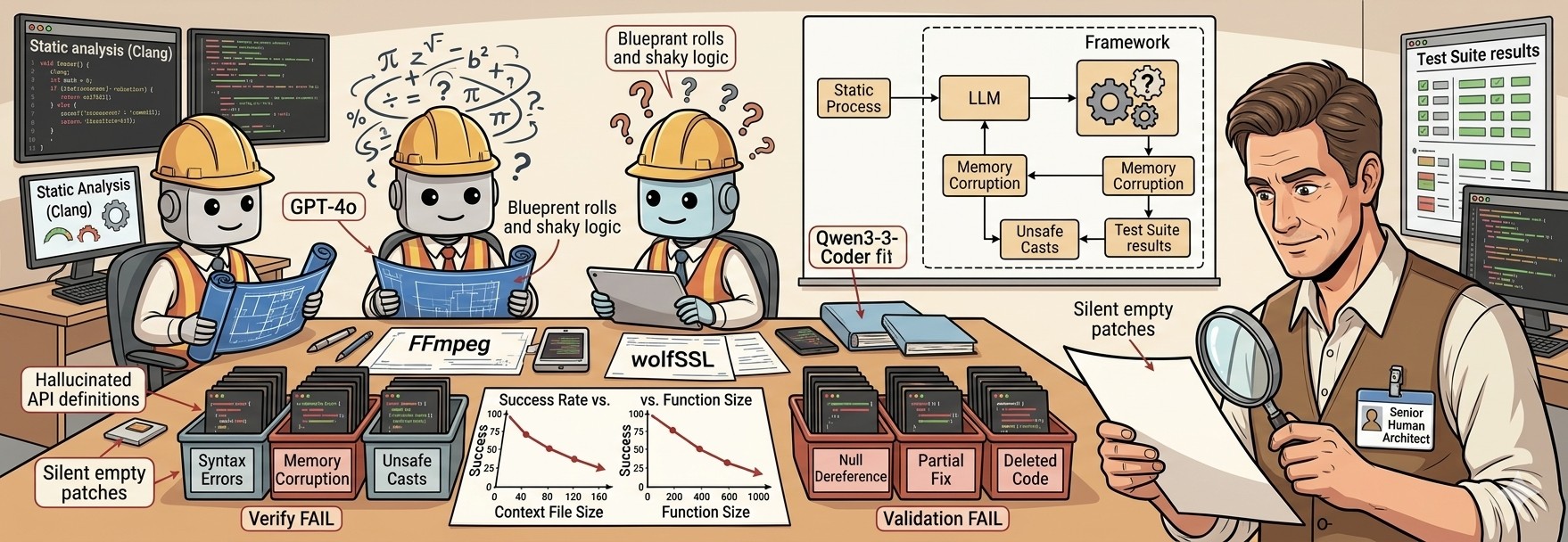
This paper puts this question to the test, because it uses actual commits from substantial, real-world open-source systems. The authors developed an automated framework to assess how suitable LLMs are at fixing bugs and adding new features to sizable code bases. They applied this framework to 212 actual commits across eight popular open-source projects—including FFmpeg and wolfSSL—and three LLMs: GPT-4o, Ministral3-14B, and Qwen3-Coder-30B.
The framework tested the generated patches on three levels:
- Verification: Does the generated code compile?
- Validation (Static Analysis): Does it pass Clang’s static analysis checkers (e.g., memory safety checks)?
- Validation (Dynamic Testing): Does it pass the project’s existing test suite?
The success rate varied wildly—from 0% on certain projects up to 60% on others. But overall, the verdict was clear: LLMs are not at a point where they can be effective contributors to production code. They still hallucinate, and they still have large limitations – at least the ones tested, we’ll see what the newest ones could do.
The Takeaway for Architects and Developers
The bottom line is clear: Do not trust LLMs de novo with critical production system code. They are effective for small functions, feature improvements, routine algorithms, and tasks similar to those seen in their training data.
However, the risk of “silent failures,” new security vulnerabilities, and logic regression means that rigorous human validation remains the most important step when integrating AI-generated contributions. Still, even in 2026!