
Image taken directly from the paper
https://arxiv.org/pdf/2605.24138
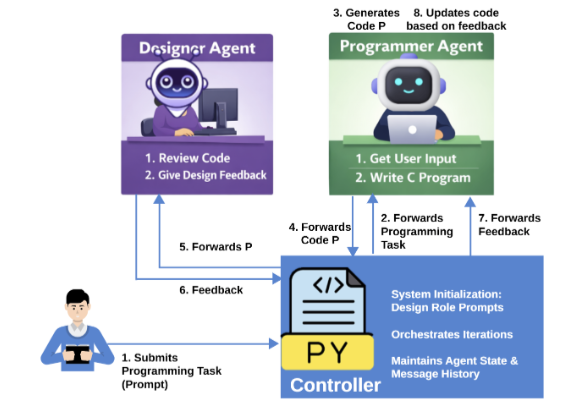
The Software Engineering (SE) landscape is shifting from LLM-assisted workflows, like copilots, toward Autonomous SE, where multiple specialized AI agents cooperate without a human in the loop. The premise is exciting: a ‘Designer’ agent creates the plan, and a ‘Programmer’ agent implements it. Yet, simply letting agents talk to each other does not reliably lead to correct or stable solutions. In our new paper, my colleagues and I undertake a systematic analysis to understand why.
We explored conversations between a Designer and a Programmer across 12 combinations from 7 leading open-source models—including Gemma 2/3, LLaMA 3.2/3.3, Qwen3, and the reasoning-focused DeepSeek-R1—as they tried to build a mathematical game in C (Fibonacci). We found that the interactions are complex, non-linear, and prone to surprising failures.
Echo Chambers Instead of Collaboration
One of our most critical, blog-worthy findings is that common metrics used to measure conversational “success,” like high BLEU and ROUGE scores (which track semantic alignment), can be misleading. In mismatched pairs, particularly involving non-reasoning models (like Gemma 3 or MiniCPM) paired with reasoning models (DeepSeek-R1), high scores were a red flag for “semantic echoing.” The Programmer agent simply mirrored the Designer’s output verbatim, which was a conversational failure, not a collaborative victory.
DeepSeek-R1: The Lone Convergent Pair
In terms of actual solution correctness, the results were stark. Only a single agent pair—DeepSeek-R1 paired with itself—was unique in immediately converging to the correct solution and sustaining it consistently to the final iteration. This indicates that while reasoning capabilities are crucial, stable collaboration currently depends more on consistent role conditioning. Our manual inspections showed that DeepSeek-R1:DeepSeek-R1 prioritized design discussion over echoing, which contributed to its success despite having some “No Code Found” instances, often related to compilation instructions.
Talking Themselves Out of Success: The Threat of Drift
We also identified a critical trend we call “behavioral stagnation” and “drift.” Multiple promising pairs—including Qwen3:DeepSeek-R1, DeepSeek-R1:LLaMA 3.3, and even a same-model pair, LLaMA 3.3:LLaMA 3.3—actually started with the correct solution. However, they subsequently talked themselves out of it, diverging to other topics (like related number theories or other code snippets) and never converging again.
As we noted in our analysis, late recovery from this kind of drift is unlikely. This provides an essential behavioral signal for SE tools developers: you must monitor the health of the interaction trace (for repetition, topic drift, or role instability) in real-time, rather than relying solely on whether code is eventually produced. Monitoring these conversational patterns can inform early stopping conditions or trigger prompt revisions before computational time is wasted on non-productive exchanges.
The Takeaway
As Software Engineering transitions to autonomous agent teams, understanding and calibrating these multi-agent interaction dynamics is critical. Strong semantic alignment does not ensure correctness, and reasoning capability alone does not guarantee stable collaboration. You need clear role separation, pair compatibility, and robust monitors that can detect conversational drift. Success isn’t a final code snippet; it’s a healthy conversation.







{kind=link}