Image generated by Gemini based on this blow post
https://www.mdpi.com/2076-3417/16/10/4788
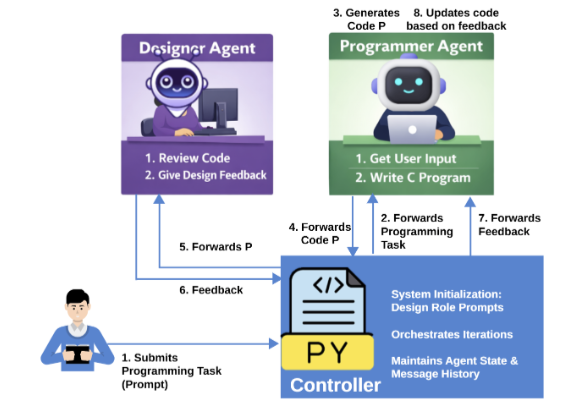
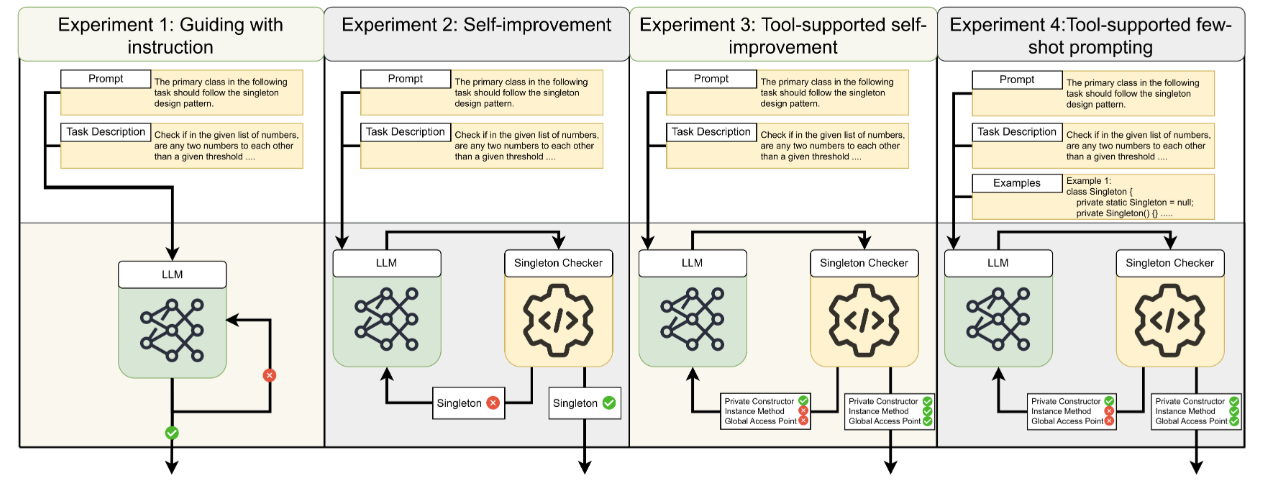
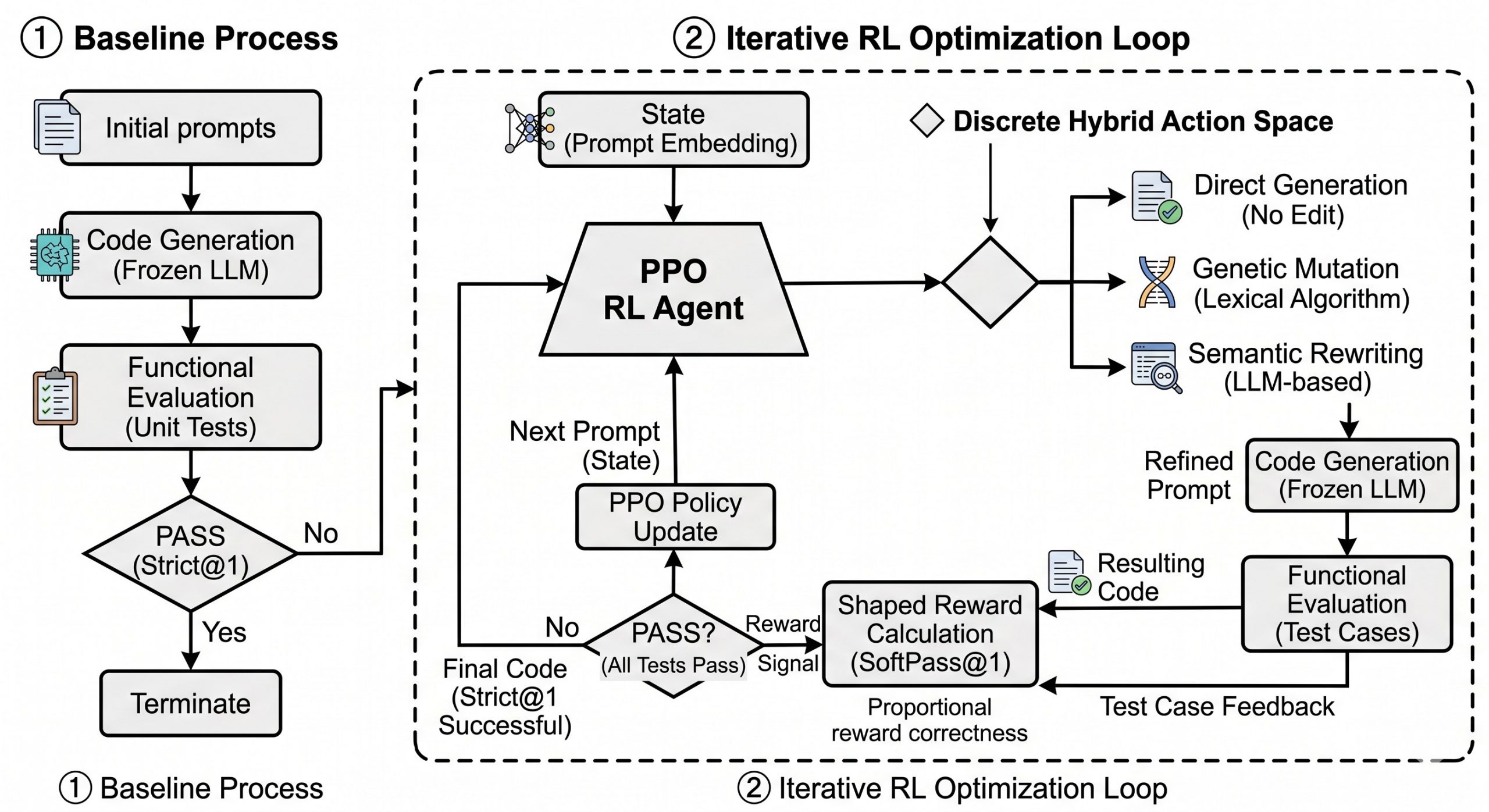
The practical meaning of automated code generation is shifting rapidly. What was recently categorized as simple “autocomplete” has expanded into complex workflows involving multi-file modifications, test execution, and repository navigation. However, as Zhenhan Chen et al. argue in a recently published article in Applied Sciences, the software engineering community still lacks a shared, operational language to describe exactly how much work is being delegated to these AI systems.
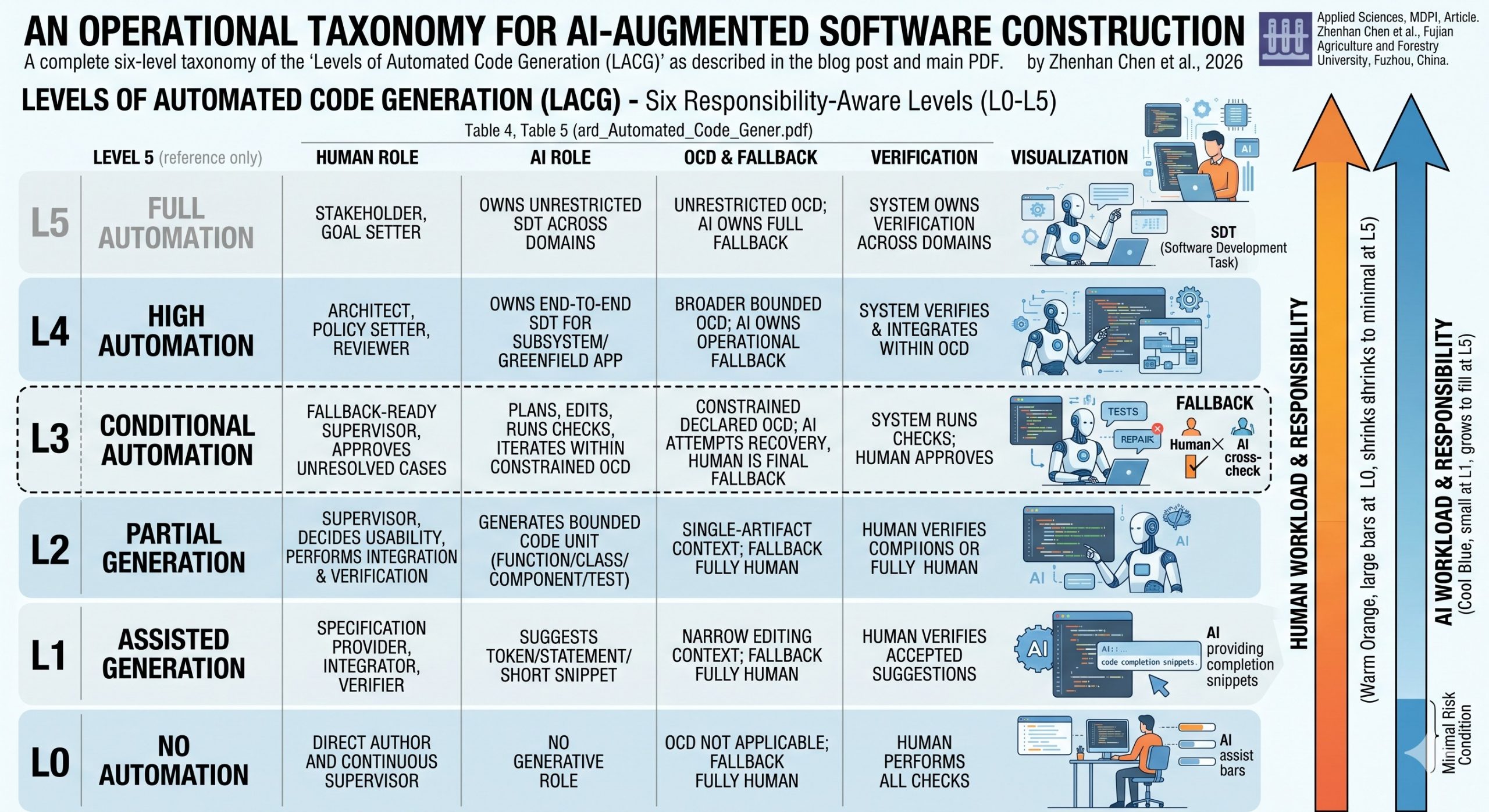
To fill this critical gap, the researchers proposed “Levels of Automated Code Generation” (LACG), a six-level taxonomy (L0 to L5) designed to classify the degree of automation in AI-augmented software construction.
The proposed levels include:
- L1 (Assisted Generation): Localized, token-level assistance (e.g., inline completion) with full human fallback.
- L2 (Partial Generation): Generation of complete code units (e.g., functions, classes) from prompts, still requiring human integration and verification.
- L3 (Conditional Automation): The system executes multi-step tasks (e.g., bug fixes, feature implementation) within a constrained OCD. The human is the final fallback.
- L4 (High Automation): The system autonomously manages end-to-end development of subsystems within a broader OCD and owns the operational fallback.
- L5 (Full Automation): Unrestricted software engineering across any domain, owning all fallback and recovery duties.
Conclusion
The LACG taxonomy provides a disciplined, operational vocabulary necessary for future empirical work, benchmark design, and reasoning about responsibility allocation in AI-augmented coding. While the study demonstrates the framework’s applicability, the authors clarify that it does not serve as a prediction of tool performance, security, or productivity outcomes