In the recent weeks I’ve turned into a specific part of my work, i.e. security vulnerability detection. In many areas, working with security has focused on the entire chain. And that’s a good thing – we need to understand when and where we have a vulnerability. However, that’s not what I can help with, which has never really stopped me before.
So, I was looking for more programmatic view on security. To be more exact, I wonted to know what we, as software engineers, need to focus on when it comes to cyber security. We can, naturally, measure it, but that’s probably not the only thing. We can analyze libraries from OSS communities to find which ones could be exploited. We can even program in a specific way to minimize the risk of the exploitation.
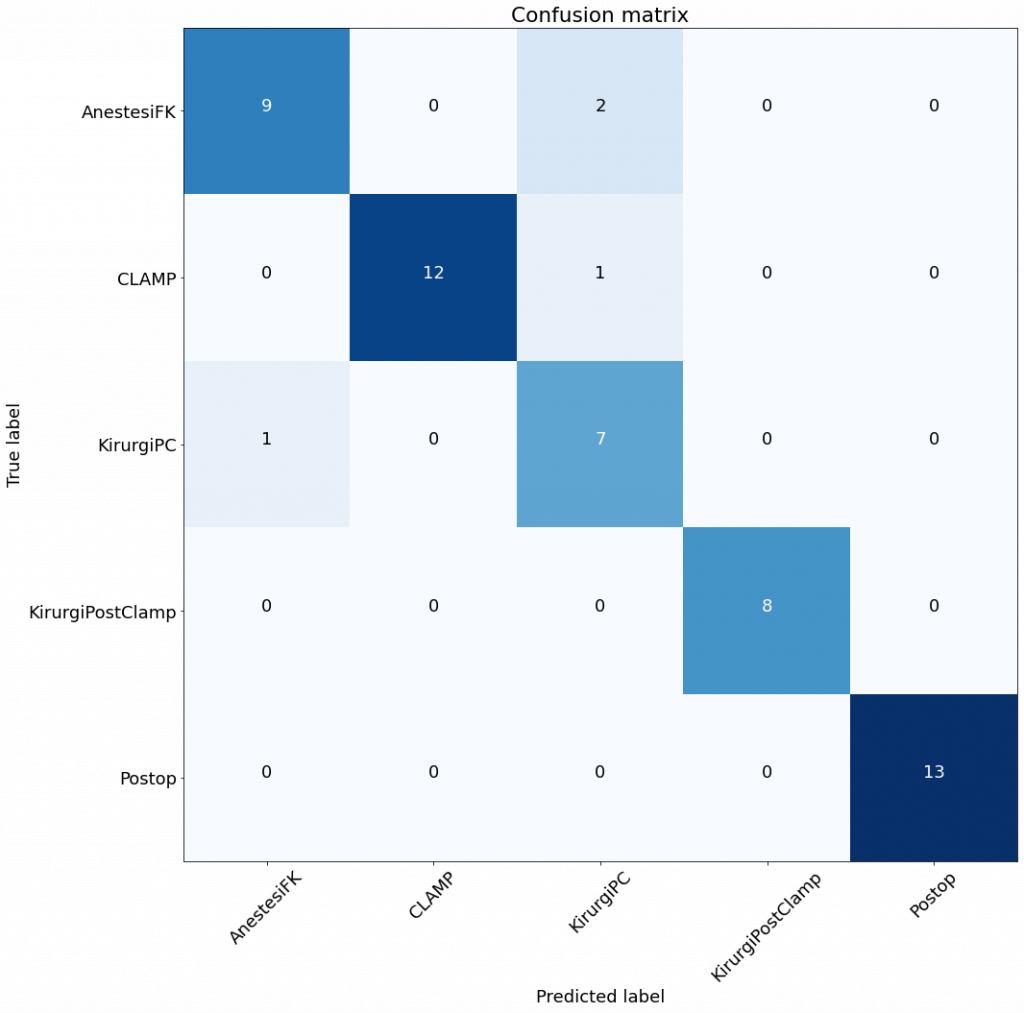
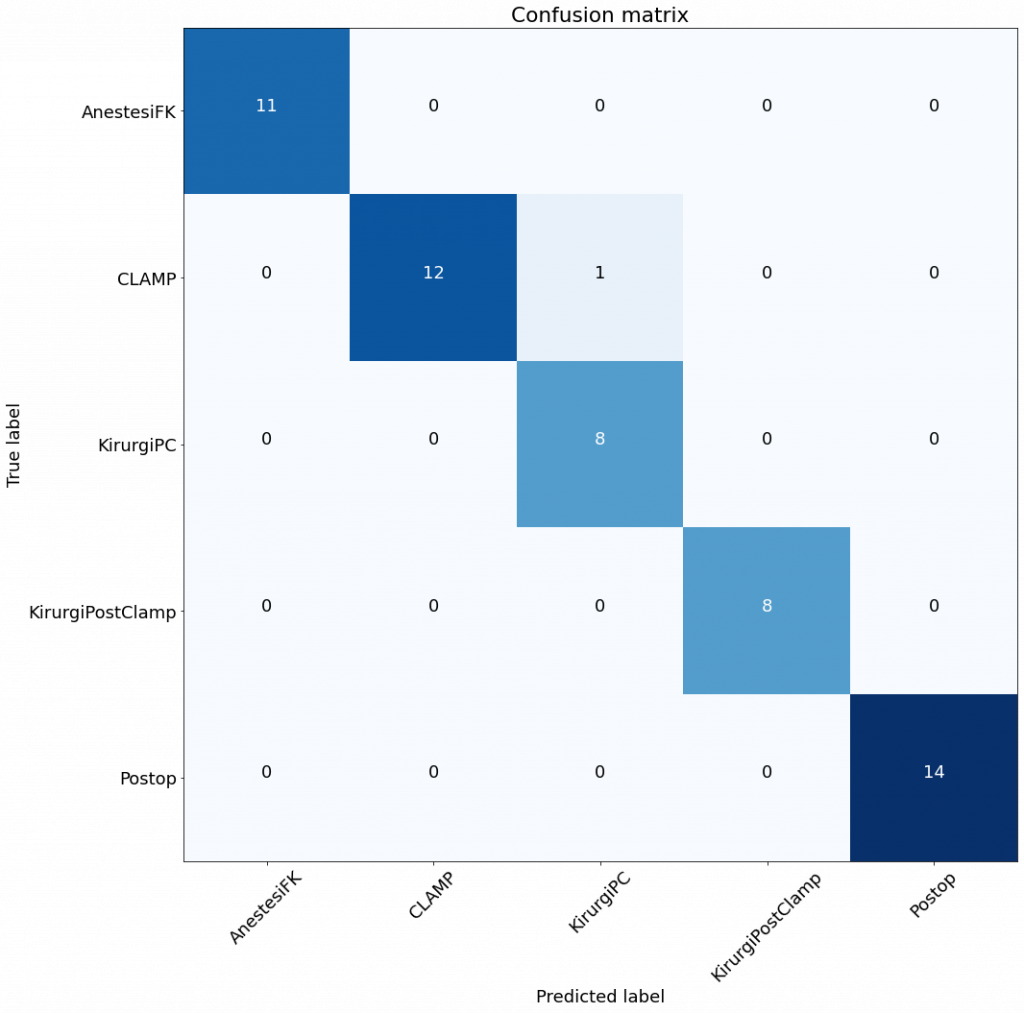
In this paper, the authors compare two different techniques for software vulnerability prediction – static software analysis and vulnerability prediction models. They have identified 12 different findings, of which the following are the most interesting ones:
- SVP models are generally a bit better when it comes to precision and overall preformance.
- SVP models provide fewer files to inspect as the output, which saves the cost.
- The two approaches lack synergy, and it’s difficult to use them together to increase their performance.
Since they have compared only a few tools, I believe it’s important to do more experiments. It is also important to understand whether it is good or bad to have fewer files to inspect – I mean, one undetected vulnerability can be very costly…