
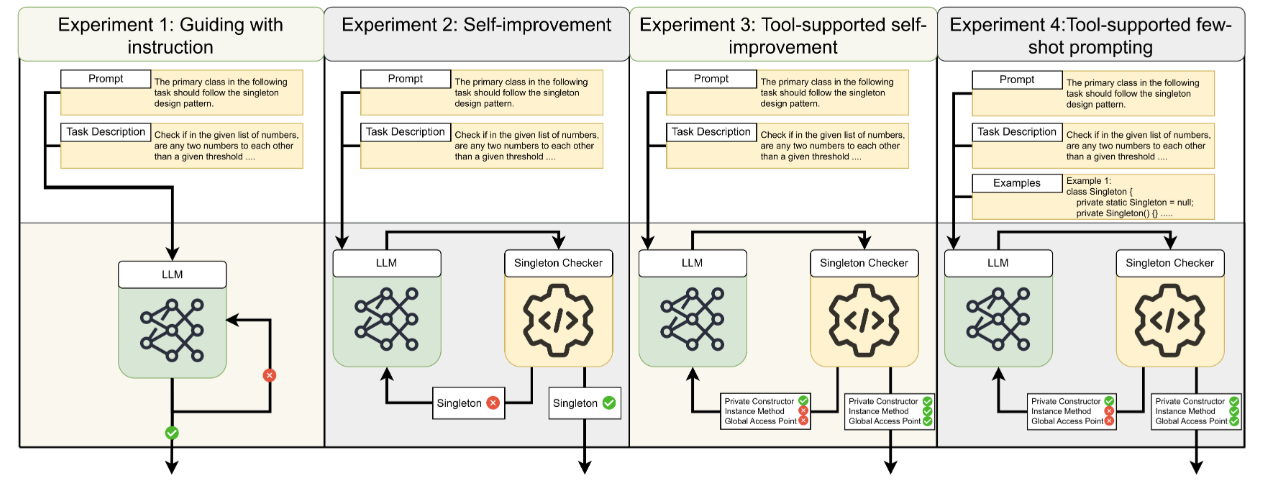
Experiment design – from the paper
Large Language Models (LLMs) are revolutionary for programming productivity, producing functional code snippets in seconds. However, as software engineers, my co-authors and I know that “functional” is not the same as “well-designed.” LLMs are generally “bottom-up” thinkers; they excel at local syntax but struggle to adhere to higher-level architectural structures or design patterns, which are crucial for long-term software maintainability and scalability.
In our new paper, presented at PROMISE ’26, we set out to answer a critical question: How can we best guide LLMs to incorporate design patterns into their generated code without sacrificing functional correctness?
We decided to use the standard Singleton creational pattern as our case study due to its easily identifiable predicates. We designed a computational experiment evaluating 13 state-of-the-art LLMs (including GPT-4o Mini, Llama 3.3, and Qwen 3) across 164 Java coding challenges from HumanEval-X. We tested four distinct prompting strategies: simple natural language instructions, iterative binary automated feedback (“Is it Singleton? Yes/No”), extensive automated feedback identifying exactly which Singleton properties were missing, and extensive feedback combined with few-shot examples.
Our findings reveal that there is no one-size-fits-all prompting solution; the optimal strategy is highly model-dependent. However, a major takeaway is that even simple strategies work remarkably well. Overall, iterative binary feedback provided the best balance, maximizing alignment with the Singleton pattern while preserving or even improving the code’s functionality.
Surprisingly, enforcing design principles didn’t always hurt performance. For strong models like Llama 3.3, just instructing it to use Singleton resulted in 100% pattern adherence and actually increased functional test pass rates by 34 percentage points compared to the baseline.
Our study proves we can teach LLMs good design habits using automated feedback loops. You can read the full paper and access our experimental data here https://arxiv.org/pdf/2605.26898.






