It’s hard to believe that 2026 is already halfway and the summer is upon us. When I look back at what happens now, I still think that the best time to be a software engineer is now. We get so many cool tools to work with that we do not want to stop working. The technology is becoming more powerful and our expertise is needed increasingly often.
First, we need to design software. Maybe I’m biased because of the topic of my PhD, but this is what I really like doing: getting dirty with the code and the design. Now, I can do more of that, reducing my frustrations with defects to zero. Why should I care? Claude and Codex can fix that for me! Ok, I do exaggerate, they are not perfect and sometimes I just need to rewrite the code myself, but hey, I can still do it.
Second, we need to define intents and specifications. That part is not my favorite because it means more requirements. Requirements are not something that I particularly like. There is nothing wrong with them; it’s just not my cup of tea (or coffee, choose the beverage of your liking). Now, I can work with requirements a bit more because I have the AI to help me with them. I do not need to work so much with the form; I can focus on what I want. So, I’ve learned meta-prompting and meta-specifications, which are really cool.
Third, we need to create guardrails – functional, development, non-functional. I’ve worked on a cool project together with my students and one of the companies, which opened up my eyes to just how important guardrails are. I’ve also realized how cool it is to work with them – it’s like setting prerequisites for learning for someone else, but that someone else is software. Take a look at our example and, if you like it contribute: https://github.com/miroslawstaron/elevator_runtime_guardrail_simple
Finally, we can learn faster because the new tools provide us with the right support for that. No more StackOverflow or community questions, we have Gemini, Claude, ChatGPT, Antigravity, you name it, that help us learn new things. They can even write things for us in the right format – you like a book chapter, here it comes; you like a paper, no problem at all; or maybe just a PowerPoint with some examples, we can do that too.
I’m looking forward to what the next year brings and how we will tackle new challenges. OpenAI usually releases things in the summer, so I hope to see something really new and cool now.
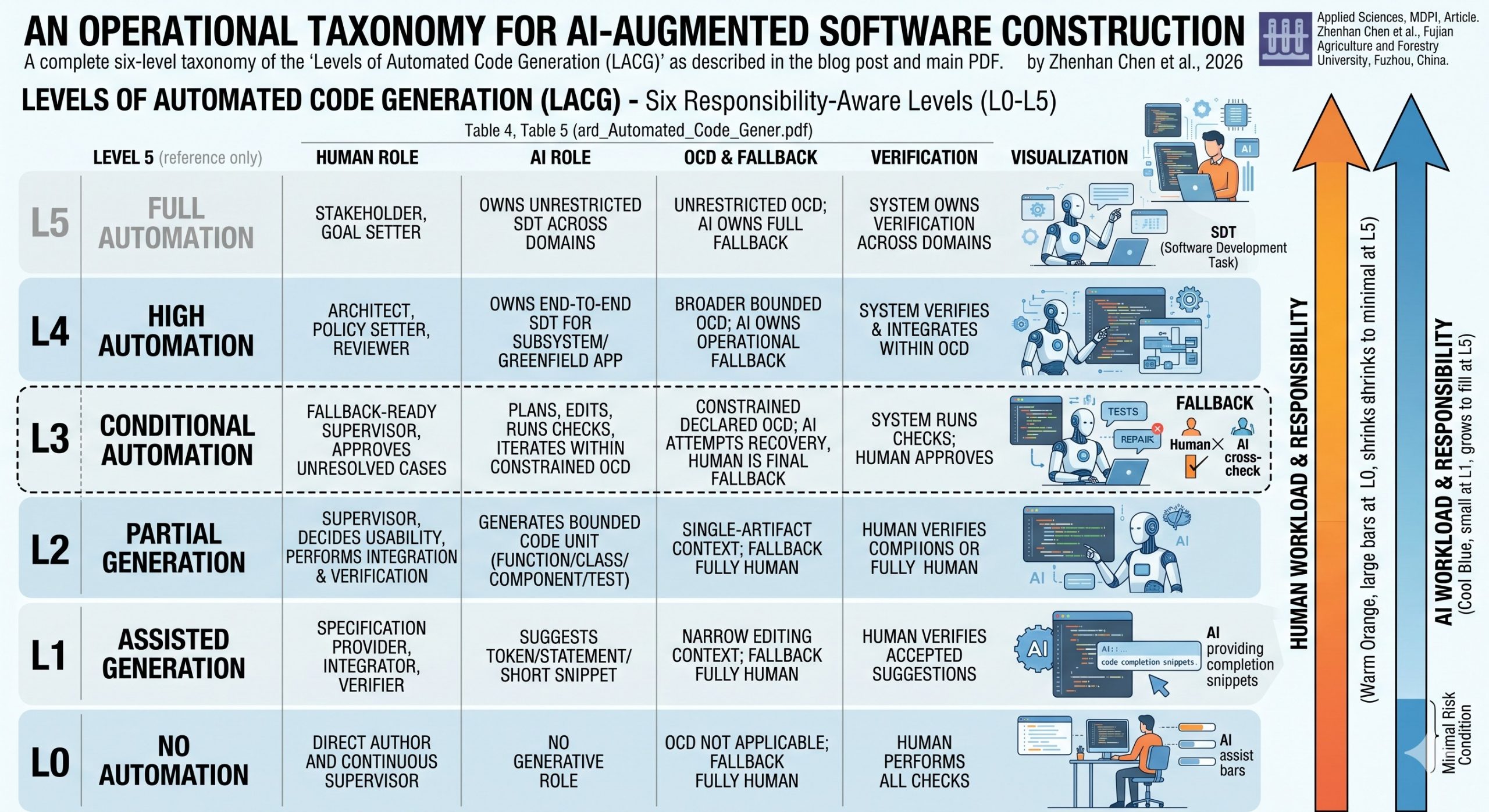
The practical meaning of automated code generation is shifting rapidly. What was recently categorized as simple “autocomplete” has expanded into complex workflows involving multi-file modifications, test execution, and repository navigation. However, as Zhenhan Chen et al. argue in a recently published article in Applied Sciences, the software engineering community still lacks a shared, operational language to describe exactly how much work is being delegated to these AI systems.
To fill this critical gap, the researchers proposed “Levels of Automated Code Generation” (LACG), a six-level taxonomy (L0 to L5) designed to classify the degree of automation in AI-augmented software construction.
The proposed levels include:
L1 (Assisted Generation): Localized, token-level assistance (e.g., inline completion) with full human fallback.
L2 (Partial Generation): Generation of complete code units (e.g., functions, classes) from prompts, still requiring human integration and verification.
L3 (Conditional Automation): The system executes multi-step tasks (e.g., bug fixes, feature implementation) within a constrained OCD. The human is the final fallback.
L4 (High Automation): The system autonomously manages end-to-end development of subsystems within a broader OCD and owns the operational fallback.
L5 (Full Automation): Unrestricted software engineering across any domain, owning all fallback and recovery duties.
Conclusion
The LACG taxonomy provides a disciplined, operational vocabulary necessary for future empirical work, benchmark design, and reasoning about responsibility allocation in AI-augmented coding. While the study demonstrates the framework’s applicability, the authors clarify that it does not serve as a prediction of tool performance, security, or productivity outcomes
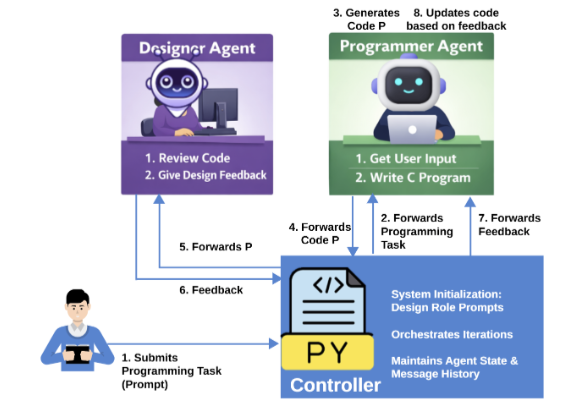
The Software Engineering (SE) landscape is shifting from LLM-assisted workflows, like copilots, toward Autonomous SE, where multiple specialized AI agents cooperate without a human in the loop. The premise is exciting: a ‘Designer’ agent creates the plan, and a ‘Programmer’ agent implements it. Yet, simply letting agents talk to each other does not reliably lead to correct or stable solutions. In our new paper, my colleagues and I undertake a systematic analysis to understand why.
We explored conversations between a Designer and a Programmer across 12 combinations from 7 leading open-source models—including Gemma 2/3, LLaMA 3.2/3.3, Qwen3, and the reasoning-focused DeepSeek-R1—as they tried to build a mathematical game in C (Fibonacci). We found that the interactions are complex, non-linear, and prone to surprising failures.
Echo Chambers Instead of Collaboration
One of our most critical, blog-worthy findings is that common metrics used to measure conversational “success,” like high BLEU and ROUGE scores (which track semantic alignment), can be misleading. In mismatched pairs, particularly involving non-reasoning models (like Gemma 3 or MiniCPM) paired with reasoning models (DeepSeek-R1), high scores were a red flag for “semantic echoing.” The Programmer agent simply mirrored the Designer’s output verbatim, which was a conversational failure, not a collaborative victory.
DeepSeek-R1: The Lone Convergent Pair
In terms of actual solution correctness, the results were stark. Only a single agent pair—DeepSeek-R1 paired with itself—was unique in immediately converging to the correct solution and sustaining it consistently to the final iteration. This indicates that while reasoning capabilities are crucial, stable collaboration currently depends more on consistent role conditioning. Our manual inspections showed that DeepSeek-R1:DeepSeek-R1 prioritized design discussion over echoing, which contributed to its success despite having some “No Code Found” instances, often related to compilation instructions.
Talking Themselves Out of Success: The Threat of Drift
We also identified a critical trend we call “behavioral stagnation” and “drift.” Multiple promising pairs—including Qwen3:DeepSeek-R1, DeepSeek-R1:LLaMA 3.3, and even a same-model pair, LLaMA 3.3:LLaMA 3.3—actually started with the correct solution. However, they subsequently talked themselves out of it, diverging to other topics (like related number theories or other code snippets) and never converging again.
As we noted in our analysis, late recovery from this kind of drift is unlikely. This provides an essential behavioral signal for SE tools developers: you must monitor the health of the interaction trace (for repetition, topic drift, or role instability) in real-time, rather than relying solely on whether code is eventually produced. Monitoring these conversational patterns can inform early stopping conditions or trigger prompt revisions before computational time is wasted on non-productive exchanges.
The Takeaway
As Software Engineering transitions to autonomous agent teams, understanding and calibrating these multi-agent interaction dynamics is critical. Strong semantic alignment does not ensure correctness, and reasoning capability alone does not guarantee stable collaboration. You need clear role separation, pair compatibility, and robust monitors that can detect conversational drift. Success isn’t a final code snippet; it’s a healthy conversation.
Image source: Gemini, based on the summary of this blog post.
When I write this post, I’m sitting at a reporting workshop of Software Center, at Axis Communications in Lund. Jan has reminded us that we’ve been going on for 15 years. That’s most of my academic career and a lot of my life. Although it makes me feel old, let me reflect on what has happened and what will happen. After all, I need to live up to the nickname that my colleagues gave me – a dinosaur.
We actually started way earlier with a smaller initiative called Software Architecture Quality Center, which was only with Ericsson and the IT University of Gothenburg. In 2010, we realized that more companies need to join to make the collaboration more fruitful. It was nice, but let’s focus more on technology rather than people.
2010 was a period of rapid data growth, driven mostly by the introduction of the iPhone three years earlier. This means that we had to develop methods to rapidly develop software, so we had three themes: CI/CD – focused on processes and fast development, Architectures – focused on the structure of the software, and Metrics (where I was/still am) – focused on monitoring of quality, structure, and processes. Our focus resulted in several innovations, like Eiffel, using heatmaps, and efficient defect prediction at member companies.
Around 2015, we shifted our focus to data and began working on learning systems. Around 2020, we focused more on AI and machine learning, just as Jensen said, “AI is going to eat software.” Then, today, we see that we focus on advanced software – autoevolving systems, no architectures, multi-agentic AI systems, basically focusing on Software Engineering 4.0 or even beyond that.
I’ve analyzed the publications from Software Center, and here is what they look like.
Transition from agile development to continuous deployment
Software architecture and architecture evolution
Embedded systems software architecture
Architecture decisions
Architecture evolution and long-term maintainability
Software product lines and variability
Product-line engineering
Variability management
Legacy software product lines
Embedded and automotive software
Automotive software complexity and coupling
ISO 26262-related verification and validation
Automotive/telecom defect prediction
Requirements engineering
Experience-based requirements tools
Requirements clarification
Natural-language requirements categorization
Software ecosystems
Automotive ecosystems
Cross-organizational modeling
Software ecosystem workshops and coordination
Character of the period: This period is dominated by now classical software engineering themes: agile transformation, architecture, product-line engineering, embedded systems, and requirements. Continuous deployment appears, but mostly as an emerging transition target.
Agile research collaboration and organizational challenges
Automotive and embedded software
Automotive embedded requirements
Virtual verification ecosystems
Model use in automotive engineering
Controlled experimentation and A/B testing
Online controlled experimentation
Continuous experimentation
Experimentation at scale
Measurement and quality management
Measurement programs
Metrics for software design and architecture
Quality management under fast release cycles
Character of the period: The focus shifts from adopting agile to industrializing speed: CI/CD, DevOps, continuous experimentation, quality measurement, and technical debt become central. Automotive remains a strong application domain.
2020–2025: AI/ML systems, MLOps, federated learning, data pipelines
Main topics:
Machine learning and AI-enabled systems
Machine-learning systems engineering
AI for software analytics
ML-based test selection
ML pipelines and continuous delivery for ML systems
MLOps
MLOps frameworks
Maturity models
Trade-offs in MLOps adoption
Moving from ad hoc ML operations to systematic improvement
Federated learning
Federated learning architectures
Real-time end-to-end federated learning
Automotive federated learning case studies
Data pipelines and data-driven development
Data pipeline management
Data science driven processes
Continuous delivery for data/ML systems
Automotive software and software-intensive embedded systems
Automotive software architectures
Automotive A/B testing
Software-intensive embedded systems
Continuous deployment in embedded contexts
Testing and quality assurance
Exploratory testing
Test selection
A/B testing with limited samples
Testing in CI/CD pipelines
Requirements engineering for large-scale and automotive systems
Requirements engineering challenges
Balancing alignment and diversity of practices
Large-scale agile requirements practices
Technical debt and developer experience
Technical debt management
Developer morale
Incentives for technical debt reduction
Character of the period: This is the clear transition into AI/ML-oriented software engineering. The publication set moves from DevOps/continuous delivery for traditional software toward MLOps, federated learning, ML pipelines, AI-enabled systems, and data-driven organizations.
2025 onwards: Generative AI, LLMs, AI-assisted SE, automotive perception, ethics
Main topics:
Generative AI and AI for software engineering
Generative AI in automated software engineering
Hybrid classical-AI systems for testing and bug fixing
AI-enhanced experimentation
Large language models
Design pattern recognition using LLMs
LLM-generated graph/Cypher queries
Programming-language models
MLOps and continuous learning
MLOps adoption frameworks
Replay-based continuous learning
ML pipeline evolution
Automotive perception and vulnerabilities
Automotive software vulnerabilities
ML-based automotive perception systems
Data leakage detection for automotive perception
Ethics and requirements engineering
Ethics-driven requirements engineering
Autonomous vehicle guidelines
Cognitive biases in requirements engineering
Experimentation platforms and ecosystems
Extensible experimentation platforms
A/B test analysis at scale
Experimentation challenges in large product/service organizations
Cloud and IoT data architectures
AWS cloud data storage architectures
IoT data storage architecture comparisons
I think that we live in the most interesting times, especially as software engineers. We can focus on really cool things like innovation, ideation, and understanding domains, rather than learning exactly how pointer operations in C work. Well, I exaggerate a bit, as we still need to know what points do and how they work – and yes, if you use Rust, you still need to understand how the operating system works with the memory.
The future
In my view, the future will bring more software, better software, and more automation. Software engineers will focus on building platforms and APIs, creating guardrails, and deploying the software. We may need to get out of our comfort zone to actually talk to people, talk to our customers, and maybe even suppliers. We will constantly learn new things; AI will help us with that, and we will get better at creating more value from software than we do today.
It’s not just a dream, but a reality. OpenAI, Anthropic, and Google were started by just a few individuals. Now, we can even grow companies with the help of AI. Software Center has a mission to accelerate the adoption of new technologies, so let’s focus on the coolest of them all – Generative AI Multi-Agent Systems.
We have all seen Large Language Models (LLMs) write impressive snippets of code or debug a tricky function. AI coding editors like GitHub Copilot are increasingly adopted, with studies suggesting that up to 88% of developers report increased productivity.
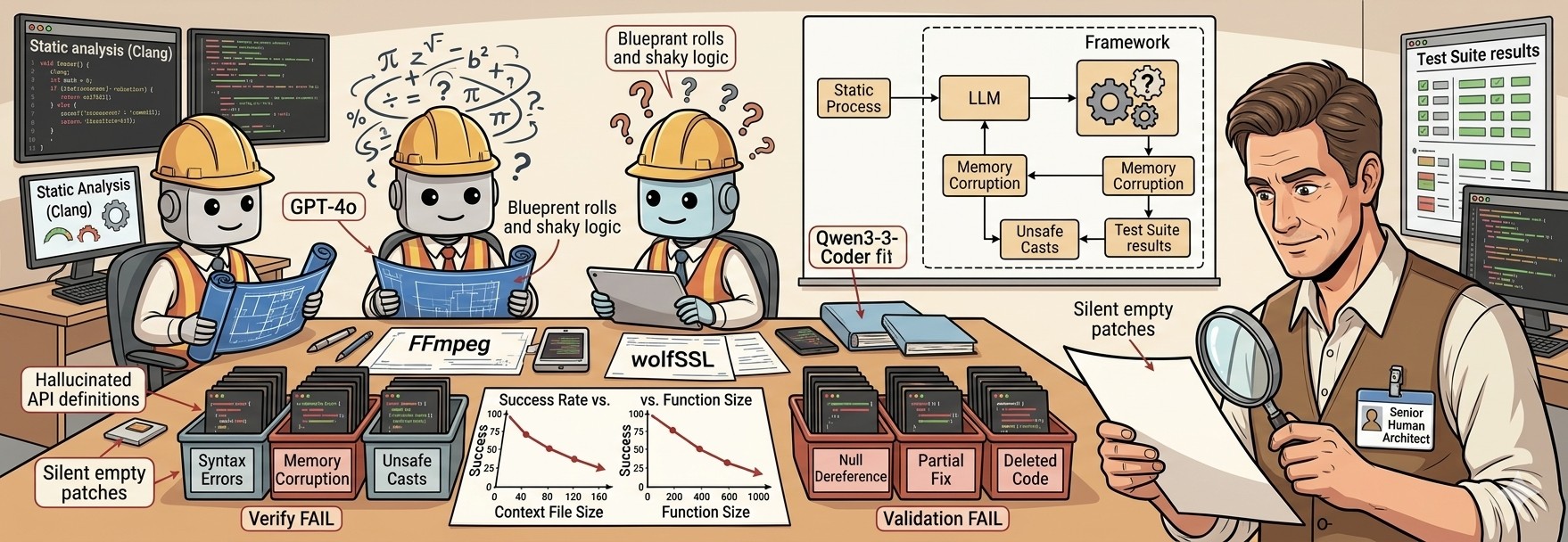
But accelerations in development come with trade-offs. Existing studies have shown that LLMs often misuse APIs, introduce security vulnerabilities, and hallucinate. So I got to wonder: Can an LLM actually understand the soul of a complex software project? Can it generate a fully automated, high-quality commit (patch) that satisfies requirements and can be directly incorporated into a major production codebase?
This paper puts this question to the test, because it uses actual commits from substantial, real-world open-source systems. The authors developed an automated framework to assess how suitable LLMs are at fixing bugs and adding new features to sizable code bases. They applied this framework to 212 actual commits across eight popular open-source projects—including FFmpeg and wolfSSL—and three LLMs: GPT-4o, Ministral3-14B, and Qwen3-Coder-30B.
The framework tested the generated patches on three levels:
Verification: Does the generated code compile?
Validation (Static Analysis): Does it pass Clang’s static analysis checkers (e.g., memory safety checks)?
Validation (Dynamic Testing): Does it pass the project’s existing test suite?
The success rate varied wildly—from 0% on certain projects up to 60% on others. But overall, the verdict was clear: LLMs are not at a point where they can be effective contributors to production code. They still hallucinate, and they still have large limitations – at least the ones tested, we’ll see what the newest ones could do.
The Takeaway for Architects and Developers
The bottom line is clear: Do not trust LLMs de novo with critical production system code. They are effective for small functions, feature improvements, routine algorithms, and tasks similar to those seen in their training data.
However, the risk of “silent failures,” new security vulnerabilities, and logic regression means that rigorous human validation remains the most important step when integrating AI-generated contributions. Still, even in 2026!
The shift from manual coding to AI-augmented orchestration is no longer a future – it is a reality. Software engineers adopt AI increasingly often and increasingly deep.
However, as organizations pour investment into Generative AI tools, a critical question remains: How do we measure the true return on investment?
I asked Gemini to analyze the DORA report and look at the internet to find how people measure AI adoption. Its report, Evaluating the Synthetic Engineer, suggests that we must move beyond vanity metrics like “lines of code generated.” When code generation is cheap, we need to think about the adoption and design.
I’ve recently heard that one company paid an eqiovalent of three software engineers worth of tokens to Anthropic, for a seven-person team. This means that effectively, 30% of the entire team (3+7) was AI. This is really cool and it shows that this reality is here. How do we measure that these tokens were not just wasted, though?
The Velocity-Quality Tension
The most immediate effect of AI is a spike in velocity. Teams often see a 15–25% reduction in Cycle Time and significantly accelerated onboarding—reducing the “Time to 10th PR” from 91 days to just 33.
However, this speed comes with a hidden cost: Comprehension Debt. The report highlights that AI-assisted code often results in higher defect density and a rework rate that can double the human baseline. To manage this, we must align AI metrics with the industry-standard DORA metrics to ensure that speed doesn’t break the system.
Integrated Metrics Framework
To truly evaluate the AI organizations should track a mix of telemetry-based system data and survey-based human sentiment.
Category
Metric
Measurement Source / Context
DORA (System)
Deployment Frequency
CI/CD Pipeline / Release logs
DORA (System)
Lead Time for Changes
Version Control / Deployment logs
DORA (System)
Change Failure Rate
Incident Management / CI/CD logs
DORA (System)
Recovery Time (MTTR)
Incident Management / Pager logs
AI Use
Acceptance Rate
IDE Plugin Telemetry
AI Use
AI Interaction Time
Tool Telemetry / Browser logs
AI Effect
Rework Rate
Jira / Commit history
Human
Trust & Reliance
Developer Surveys (Confidence in AI)
Human
Job Satisfaction
Developer Surveys (Burnout vs. Flow)
Now, we can compare that to the DORA metrics that are used widely in industry today. There, we have two parts, the telemetry based ones:
Metric
Definition
Measurement Source
Deployment Frequency
How often the team successfully releases to production.
CI/CD Pipeline / Release logs
Lead Time for Changes
Time from code commit to code successfully running in production.
Version Control / Deployment logs
Change Failure Rate
% of deployments causing a failure in production (requiring a fix/rollback).
Incident Management / CI/CD logs
Failed Deployment Recovery Time
How long it takes to restore service after a failure in production.
Incident Management / Pager logs
Rework Rate
The percentage of work time spent on unplanned fixes or bugs.
Ticket tracking (Jira) / Commit history
Acceptance Rate
The ratio of AI-generated code suggestions that are actually kept in the file.
IDE Plugin Telemetry
Commit/PR Volume
The raw count of code changes and pull requests submitted.
Version Control Systems (VCS)
AI Interaction Time
The actual duration of time spent interacting with an AI interface.
Tool Telemetry / Browser logs
Code Stability
The frequency of breaks or regressions in the automated test suite.
Testing Frameworks / Build logs
And then the ones that are measuring perceptions, based on surveys:
Metric
Definition
Context for Use
Trust
The degree of confidence a developer has in the accuracy and safety of AI output.
To identify if developers are “blindly” following AI or if skepticism is hindering adoption.
Reflexive Use
How instinctively a developer turns to AI when a new problem arises.
To measure the behavioral shift in problem-solving habits.
Reliance
The self-assessed level of dependency on AI tools to complete daily work.
To monitor for potential skill atrophy or high-dependency risks.
Individual Effectiveness
Perceived productivity, impact on the organization, and ability to stay “in flow.”
To assess the “value-add” from the developer’s own perspective.
Job Satisfaction
The level of fulfillment and contentment a developer feels in their role.
To ensure that AI automation is improving work life rather than creating “toil.”
Burnout
Physical or mental exhaustion caused by work-related stress.
To monitor if the increased “instability” caused by AI is taxing the team.
Personal Ownership
The psychological feeling of “owning” the code and its quality.
To prevent the dilution of accountability when AI generates a high volume of code.
User-Centric Focus
The extent to which the team prioritizes end-user needs in their workflow.
Used as a “multiplier” to see if AI speed is being directed at the right goals.
I recommend picking out some of these metrics and sticking to them. I personally prefer telemetry-based metrics because they provide more value than filling out a survey. Survey-based metrics should be used sparingly, as they provide more of a temperature reading for an organization.
I’m often asked what invention I think is the biggest in human history. I do not have one that is the biggest, but I have a short list:
1) Writing – once we learned how to codify knowledge, our progress accelerated tremendously
2) Computing – once we learned how to make complex calculations fast, we started to achieve the impossible – going to the Moon, communicating over the Internet, just to name a few.
3) AI – when we learned how to utilize advanced calculations to simulate intelligence, humanity achieved new heights
This book takes us through that kind of journey. It does add a few more steps, like the invention of binary calculations, the Internet, Google, etc., but in essence, it does follow the same pattern.
What the book does not cover, and what I often wonder about, is the invention of the compiler. Compilers, especially for higher-level programming languages like C, provided the abstraction needed to decouple the nitty-gritty details of computer architectures from the problems we want to solve.
We see a similar development today with LLMs and Agentic AI. It decouples the details of programs from the intents and requirements of the user. We do not need to know anything about programming to create software that does things for us. Product owners can create prototypes, requirements engineers can test their hypotheses, testers can ensure that they do not miss important corner cases – the examples can be multiplied, and that’s just software engineering.
This does not mean that software engineering is solved, as Nvidia’s CEO put it, it means that it has changed. It’s probably the most fun time to be a software engineer as we can start solving really difficult questions without the need to lose time for details of the implementations. We also need the knowledge how to design systems based on AI – how to engineer them (BTW: if you are interested in this, here is my latest book that will help you: Link).
I recommend Tom Wheeler’s book to anyone interested in the story of how we invented AI in the first place.
The VECS 2026 conference in Gothenburg has made one thing clear: the transition to Software-Defined Vehicles (SDVs) is no longer a future prediction—it is accelerating rapidly toward total market dominance. I’ve been to both days and it seems that the best time for software is NOW! For a nerdy software engineer like me, this conference provided a glimpse of the future where software defines everything, AI – yes, but complemented with a lot of good-old-fashion programming, guardrails and similar.
My Key Takeaways from the Conference:
Rapid Market Evolution: While current volumes are relatively low, the global SDV share is projected to jump from 14% in 2025 to 46% by 2035. Similarly, Zonal Architectures are expected to grow from a 5% share today to 40% by 2035.
The Rise of Middleware: Middleware is emerging as a critical control point for OEMs. To shorten time-to-market and maintain control over software platforms, OEMs are now partnering to develop joint middleware solutions rather than relying on fragmented supplier systems.
China as a Catalyst: The fast pace of Chinese automakers is a primary driver for global change, pushing the industry toward “AI-defined mobility” and the integration of edge AI models. Notably, over 20 OEMs integrated DeepSeek within weeks of its release.
The “Software Factory”: Industry leaders like Alwin Bakkenes emphasized that profitability in the electric vehicle sector requires extreme process optimization. This is being achieved through “Software Factories”—modern development concepts where source code is integrated with digital twins for virtual testing and exploration.
Hardware Innovation: To control AI workloads, OEMs are increasingly designing their own chips and moving toward 2nd Generation Zonal Architectures, such as the one powering the upcoming Volvo EX60.
The message from VECS 2026 is certain: for the automotive industry to thrive, it must embrace a “machine that builds the machine” philosophy, prioritizing high-performance computing and seamless software integration.
We’ve all seen Large Language Models (LLMs) write impressive snippets of code or debug a tricky function. But can an AI actually understand the soul of a system? Can it explain the “why” behind a complex architectural decision?
The paper, “Do Large Language Models Contain Software Architectural Knowledge? An Exploratory Case Study with GPT,” puts this to the test. Researchers did a study with 14 software engineers to see if GPT could navigate the Architectural Knowledge (AK) of a massive, real-world system: the Hadoop Distributed File System (HDFS).
The Experiment: AI vs. The Ground Truth Engineers grilled GPT with questions ranging from basic component identification to deep design rationales. Their answers were then compared against a verified “ground truth” of HDFS documentation.
The Results The study revealed a fascinating dichotomy in GPT’s performance: Recall was ok: GPT is surprisingly good at “remembering” things. It showed moderate recall, meaning it could often identify the correct architectural components and general concepts buried in its training data. Precision was really bad (guessing is much better): It struggled with accuracy. The model often suffered from lower precision, frequently providing answers that sounded authoritative but were technically incorrect or “hallucinated.”
When asked about design rationales (why a specific solution was chosen) or quality attribute solutions, GPT’s performance dipped significantly. It can tell you what is there, but it struggles to explain the engineering trade-offs.
The Takeaway for Architects The engineers in the study rated GPT’s trustworthiness as only moderate. The verdict is clear: GPT is a fantastic tool for initial discovery and brainstorming, but it cannot be used as a source of truth for critical system design.
The Bottom Line is to treat LLMs as junior architects with a photographic memory but a shaky grasp of logic. They are great for a first draft, but expert human validation remains the most important step in the process.
For years, software architects have operated in an “automation gap.” While developers enjoy robust CI/CD pipelines and automated testing, architects have largely relied on manual whiteboarding and expert intuition. With the rise of Generative AI (GenAI), many wonder: Is the gap finally closing?
In this paper, researchers provide a reality check. Their verdict? GenAI is a powerful “tutor” and “brainstormer,” but it isn’t ready to take the captain’s chair.
Where GenAI Shines
The study identifies a high “GenAI Fit” for tasks that are traditionally “loud” and creative. It excels at:
Brainstorming: Identifying potential stakeholders or generating design alternatives.
Drafting: Creating well-formed Architecturally Significant Requirements (ASRs) from raw notes.
Summarization: Condensing complex documentation into digestible views.
Where it does not fit!
However, the “gap” remains for high-fidelity tasks. GenAI struggles with objective analysis. It can’t reliably prioritize requirements, verify the correctness of architectural views, or resolve conflicting design decisions. These tasks require the subjective judgment and deep organizational context that only a human architect possesses.
The Future: Hybrid Workflows
The path forward isn’t replacing architects with bots; it’s about hybrid workflows. By pairing GenAI with traditional tools (like static analyzers) to fact-check its “hallucinations,” we can finally automate the tedious parts of architecting while leaving the critical, high-stakes decisions to the experts.
The Bottom Line: Use GenAI to widen your perspective and draft your docs, but keep your hands on the wheel when it comes to the “why” behind your system.