

As you have probably observed I’ve been into language models for code analysis, design and recognition. It’s a great way of spending your research time as it gives you the possibility to understand how we program and understand how to model that. In my personal case, this is a great complement to the empirical software engineering research that I do otherwise.
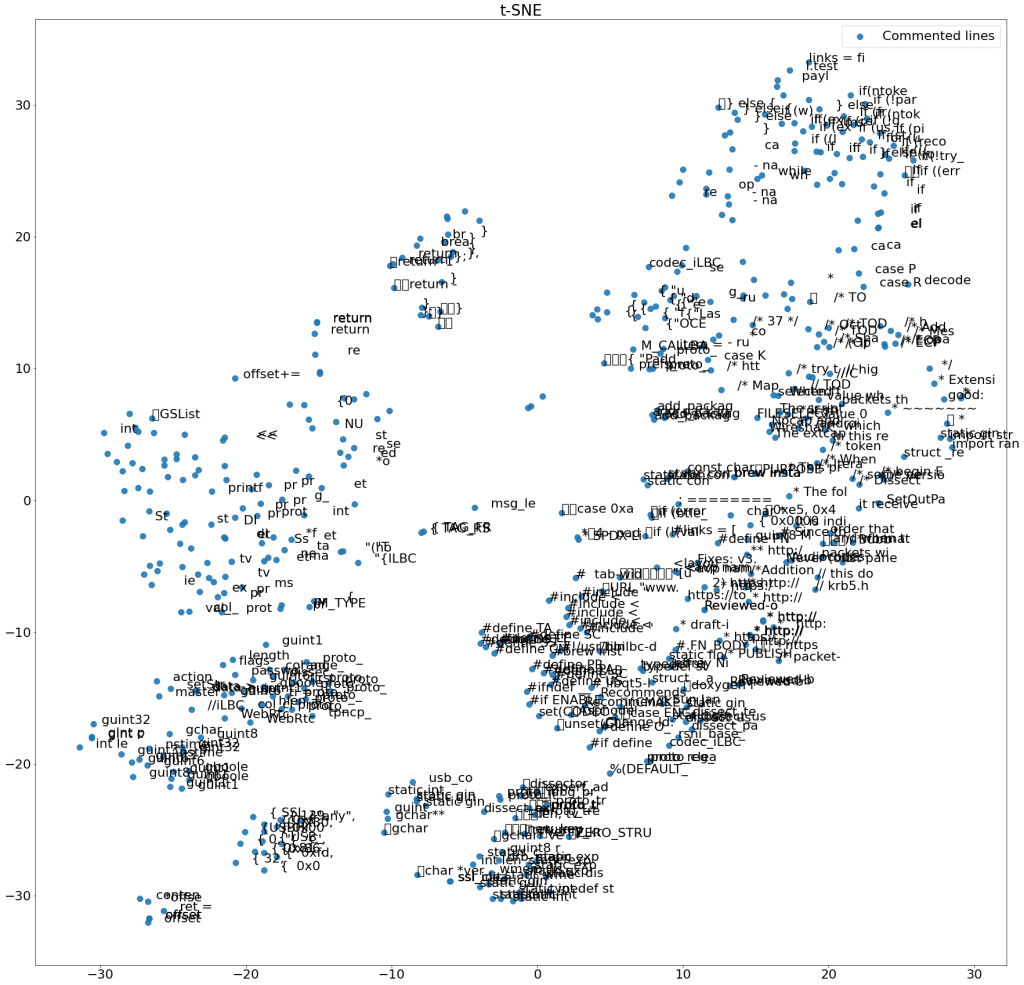
In the recent time I got a feeling that I look into more and more of these models, all of them baring certain similarity to the Google’s BERT model or the Fracebook’s TransCoder. So I set off to do a short review of the papers that actually talk about code models or, as they are often called, programming language models. I started from the paper describing CodeBERT ( [2002.08155] CodeBERT: A Pre-Trained Model for Programming and Natural Languages (arxiv.org) ) and looked at the 500 citations that the model has. The list below is just the list of the models that are created based on CodeBERT. There are also models created based on AlphaGo or Github CoPilot, but I leave these for another occasion.
I must admit that I did not read all of these papers and did not look at all of these models. Far from it, I only looked at some of them. My conclusion is that we have a lot of models, but the quality of the results vary a lot. The best models provide good results in ca. 20% of cases. AlphaCode is an example of such a model, which is fantastic, but not super-accurate all the time. As the model is used for super-competitive tasks, 20% is actually very impressive – it’s difficult to say that I would do better for these programming competitions, so I’m not criticizing.
The best model I’ve seen so far, however, is the Github CoPilot, which is by far the best model to create code that the world has seen. Well, there may be models that the world has not seen, but then they do not count. If you would like to see a preview of how I use it (part I), you can take a look at this video:
I sincerely hope that you find this list useful and that you can help me to keep it updated – drop me an e-mail about the list if you want to:
- AlphaGo: https://www.deepmind.com/blog/competitive-programming-with-alphacode
- TransCoder: https://github.com/facebookresearch/TransCoder
- CodeT5: https://arxiv.org/pdf/2109.00859
- CodeITT5: https://arxiv.org/pdf/2208.05446
- ProphetNet: https://arxiv.org/pdf/2104.08006
- Cotex: https://arxiv.org/pdf/2105.08645
- Commit2vec: https://arxiv.org/pdf/1911.07605
- CoreGen: https://www.sciencedirect.com/science/article/pii/S092523122100792X
- SyncoBERT: https://arxiv.org/pdf/2108.04556
- TreeBERT: https://proceedings.mlr.press/v161/jiang21a/jiang21a.pdf
- FastSpec: https://ieeexplore.ieee.org/iel7/9581154/9581061/09581258.pdf
- CVEFixes: https://dl.acm.org/doi/pdf/10.1145/3475960.3475985
- CodeNet: https://arxiv.org/pdf/2105.12655
- Graph4Code: https://www.researchgate.net/profile/Jamie-Mccusker-2/publication/339445570_Graph4Code_A_Machine_Interpretable_Knowledge_Graph_for_Code/links/5fd2a29a45851568d154cfaa/Graph4Code-A-Machine-Interpretable-Knowledge-Graph-for-Code.pdf
- DeGraphCE: https://dl.acm.org/doi/pdf/10.1145/3546066
- VELVET: https://ieeexplore.ieee.org/iel7/9825713/9825693/09825786.pdf
- Code2Vec: https://uwspace.uwaterloo.ca/bitstream/handle/10012/15862/Arumugam_Lakshmanan.pdf?sequence=9&isAllowed=y
- MulCode: https://ieeexplore.ieee.org/iel7/9425868/9425874/09426045.pdf
- Flakify: https://ieeexplore.ieee.org/iel7/32/4359463/09866550.pdf
- CoDesc: https://arxiv.org/pdf/2105.14220
- NatGen: https://arxiv.org/pdf/2206.07585
- Coctail: https://arxiv.org/pdf/2106.05345
- MergeBERT: https://arxiv.org/pdf/2109.00084
- SPTCode: https://dl.acm.org/doi/pdf/10.1145/3510003.3510096
- InCoder: https://arxiv.org/pdf/2204.05999
- JavaBERT: https://ieeexplore.ieee.org/iel7/9680270/9679822/09680322.pdf
- BERT2Code: https://arxiv.org/pdf/2104.08017
- NeuralCC: https://arxiv.org/pdf/2012.03225
- LineVD: https://arxiv.org/pdf/2203.05181
- GraphCode2Vec: https://arxiv.org/pdf/2112.01218
- ASTBERT: https://arxiv.org/pdf/2201.07984
- CodeRL: https://arxiv.org/pdf/2207.01780
- CV4Code: https://arxiv.org/pdf/2205.08585
- NaturalCC: https://xcodemind.github.io/papers/icse22_naturalcc_camera_submitted.pdf
- StructCode: https://arxiv.org/pdf/2206.05239
- VulBERT: https://arxiv.org/pdf/2205.12424
- CodeMVP: https://arxiv.org/pdf/2205.02029
- miBERT: https://ieeexplore.ieee.org/iel7/9787917/9787918/09787973.pdf?casa_token=rPNbu-k9Gh4AAAAA:3lkZVyUjnDP4Sp1UmmO9eVftsRaf1zAuw1YhHQogsyDBE2Y7992gBlhPb9jKVcI-5Q8tTv2JEyQ
- LineVUL: https://www.researchgate.net/profile/Chakkrit-Tantithamthavorn/publication/359402890_LineVul_A_Transformer-based_Line-Level_Vulnerability_Prediction/links/623ee3d48068956f3c4cbede/LineVul-A-Transformer-based-Line-Level-Vulnerability-Prediction.pdf
- CommitBART: https://arxiv.org/pdf/2208.08100
- GAPGen: https://arxiv.org/pdf/2201.08810
- El-CodeBERT: https://dl.acm.org/doi/pdf/10.1145/3545258.3545260?casa_token=DNyXQpkP69MAAAAA:y2iJC3RliEh7yJ6SzRpRRKrzPn2Q6w25vpm5vpoN0TksDh_SbmVfa_8JcDxvVN8FydOL_vTJqH-6OA
- COCLUBERT: https://ieeexplore.ieee.org/iel7/9679834/9679948/09680081.pdf?casa_token=FtrqlHTmm74AAAAA:kkMyRsMl9xqPQQSBTRd6vFD-2-DyVSomYBYqm8u8aKs7B0_rkYYfL_OLVmOHgzn1-vqMF6W7pM8
- Xcode: https://dl.acm.org/doi/pdf/10.1145/3506696?casa_token=5H8iW3e2GlYAAAAA:m2QA-DXSk5LZYazFxDPEVfLZcYREqDomXNg5YmkR-rPllHD37Qd8eLw_SCu6rbhNHZJ2Od24dvJt_Q
- CobolBERT: https://arxiv.org/pdf/2201.09448
- SiamBERT: https://melqkiades.github.io/files/download/papers/siambert-sais-2022.pdf
- CodeReviewer: https://arxiv.org/pdf/2203.09095
- CodeBERT-nt: https://arxiv.org/pdf/2208.06042
- BashExplainer: https://arxiv.org/pdf/2206.13325





{kind=link}