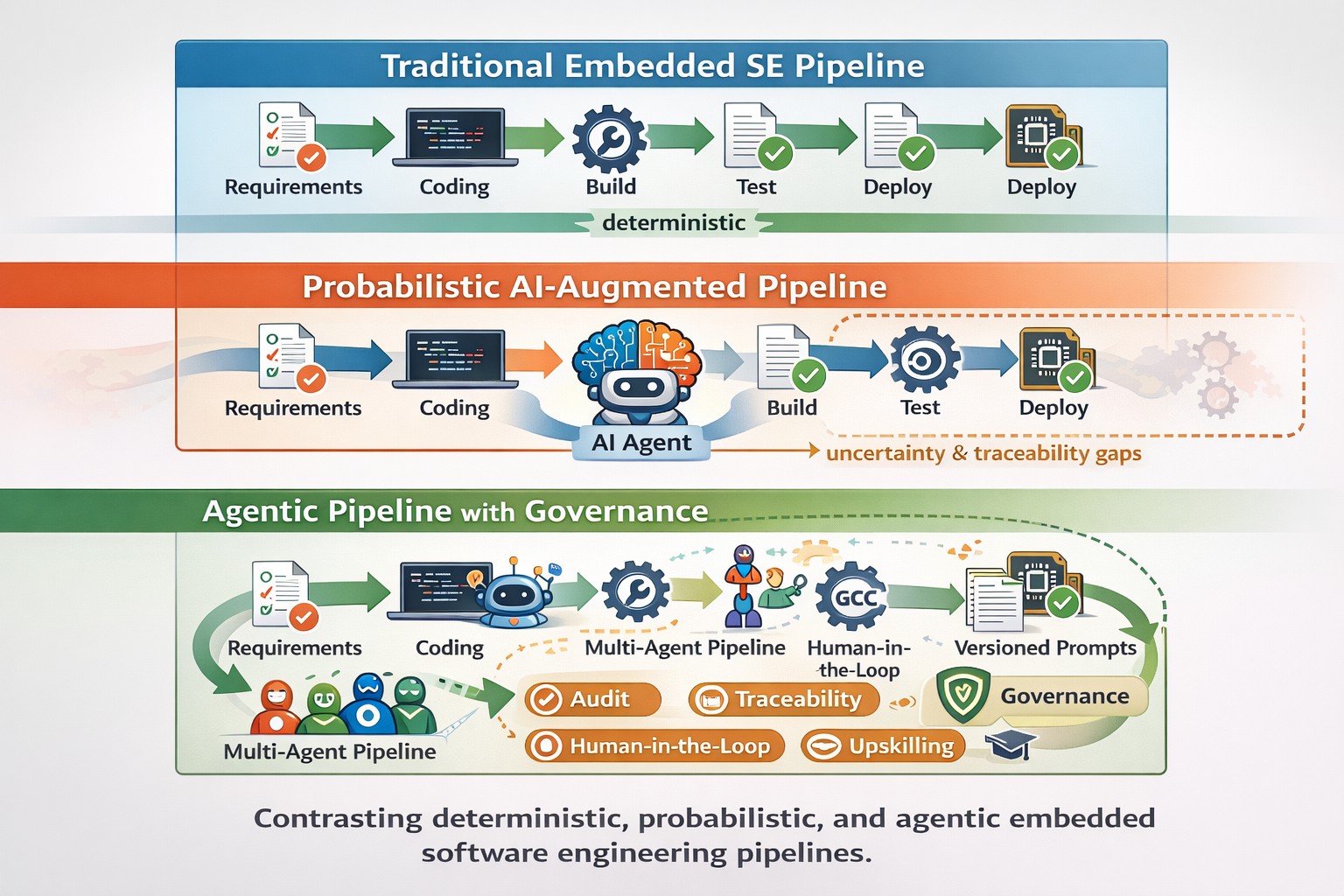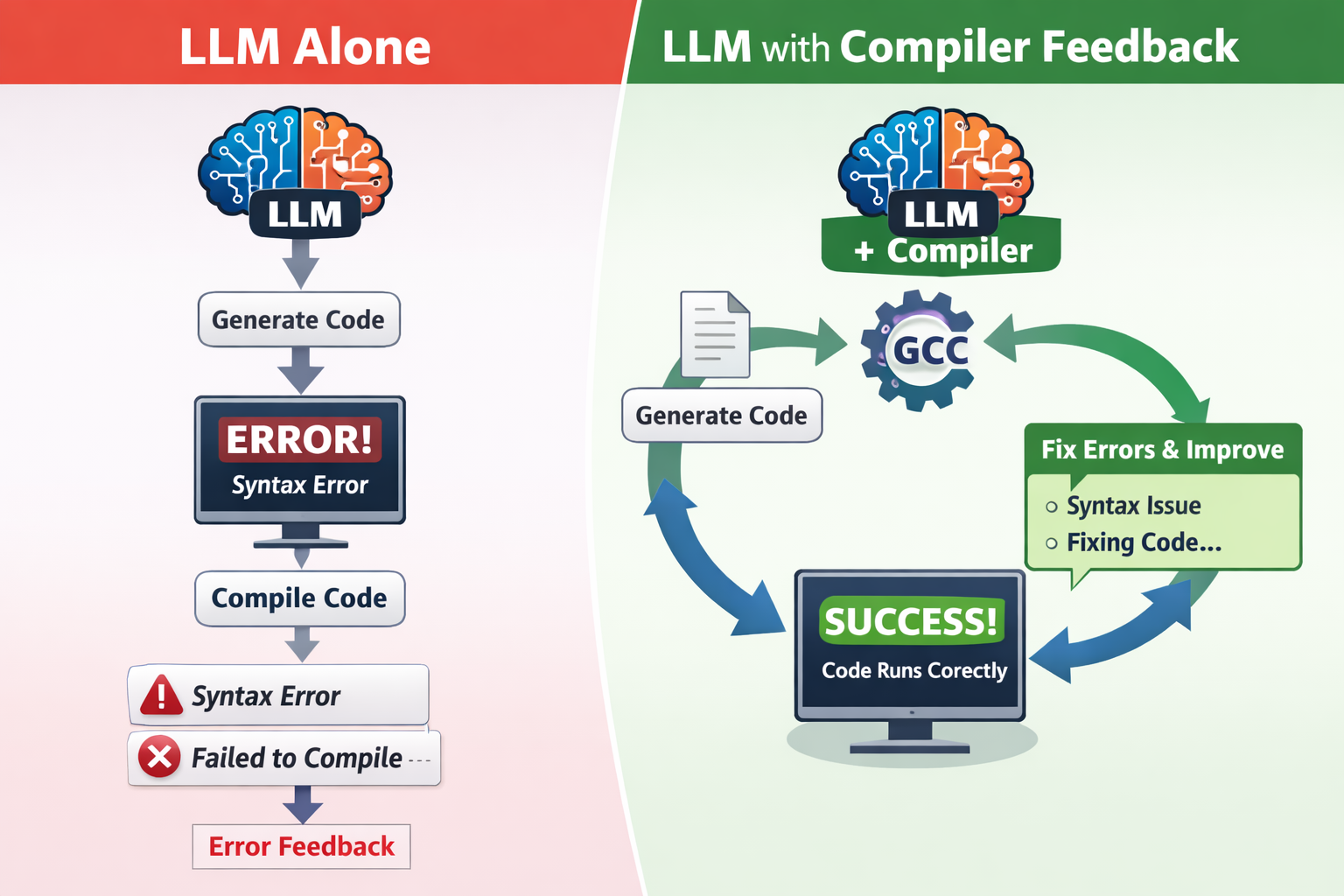
In the world of microservices, we often chase the dream of independent deployment, rapid scaling, and resilient services. We focus on the dynamic—the Kubernetes pods autoscaling, the latency spikes, the load balancer metrics. We assume that if we have a robust runtime, our architecture is sound.
But this study suggests we have been ignoring a crucial connection. We are too often treating the symptoms, not the disease.
The research team, using the massive Train Ticket benchmark system, decided to prove something architects have suspected for years: The way you draw your boxes and arrows directly dictates your application’s carbon footprint and response time.
They didn’t just guess; they used advanced tooling to quantify the chaos. By combining service call dependency mapping with Design Structure Matrices (DSM) that also tracked subtle entity-sharing (services talking behind each other’s backs via a shared database), they revealed invisible architectural decay. They matched static Architecture Antipatterns (e.g., “Cliques”—tightly clustered groups that must change together) against dynamic Performance Antipatterns (e.g., “Blobs”—services that become bottlenecks).
The results are a wake-up call for any DevOps team trying to scale a legacy monolith that’s masquerading as microservices.
A Roadmap to Technical Debt Management
The impact on practice is clear. This study validates that we must merge static and dynamic analysis. We cannot separate the “Dev” and “Ops.”
Stop Guessing: You cannot optimize what you cannot measure. Utilize tooling that visualizes both runtime traffic and structural dependencies.
Prioritize Refactoring: Performance monitoring based on real operational profiles tells you where the bottleneck is. Combining this with architecture analysis tells you why it is there and which structural repair will deliver the greatest performance ROI.
Green Your Code: Every redundant service call, every unneeded database join, and every “Chatty Service” antipattern is wasted energy. Good architecture is sustainable architecture.
It’s time to stop thinking that Kubernetes will save your tangled architecture. The next time you see a latency spike, don’t just add more pods. Check your blueprints. The fastest system is one that doesn’t have to do unnecessary work.