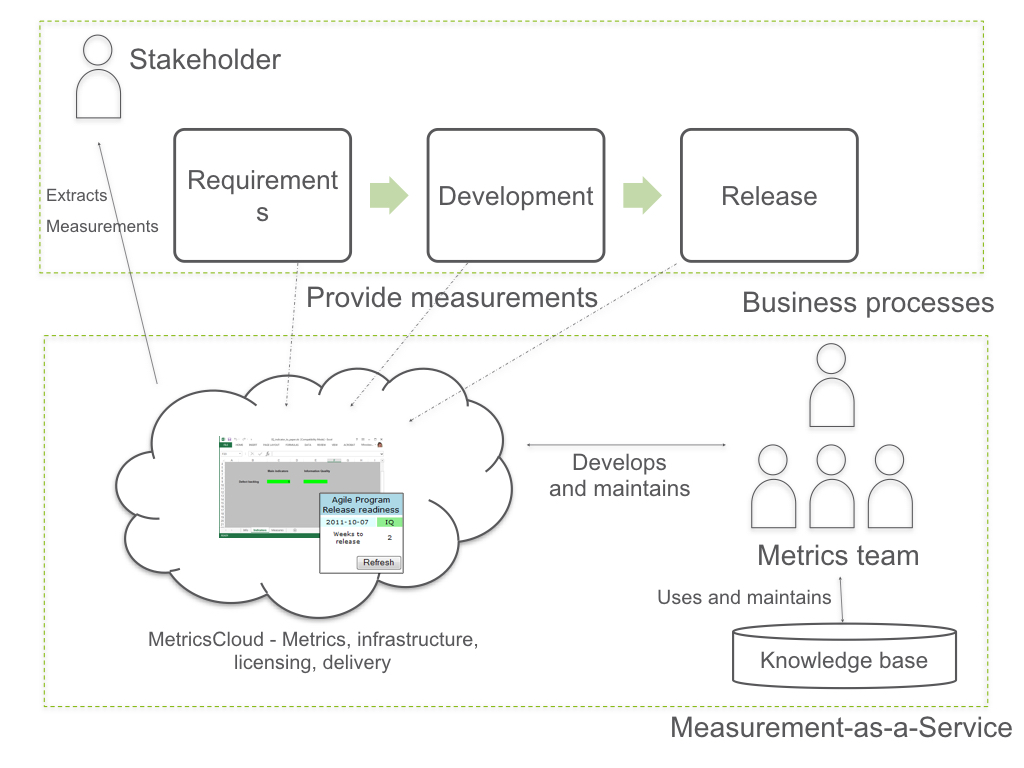
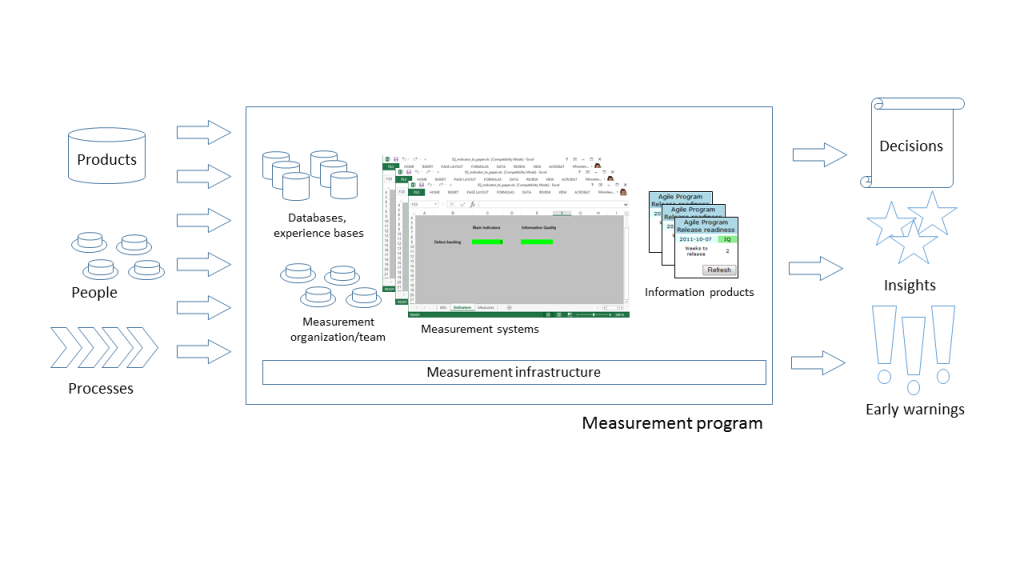
Investigating diversity and impact of the popularity metrics for ranking software packages (review): https://onlinelibrary-wiley-com.ezproxy.ub.gu.se/doi/pdfdirect/10.1002/smr.2265

I’ve written about the ways of assessing how good software is. One of the modern approaches, which I talked about before, is the use of A/B testing and online experiments. Providing the users with different versions of the features/systems/use cases allows the company to understand which of the options provides the best response from the users.
However, there are a number of challenges with this approach – the most prominent being the potential existence of confounding factors. Even if the results show a positive/negative response, we do not really know whether the response is not caused by something else (for example by users being tired, changes in the environment, etc.)
After using GitHub, both as a user and as a researcher, I sometimes wondered whether the star system is actually the right one. I wondered whether we should use a sort-of A/B testing system where we could check how often people usually access certain repositories.
In this paper, the authors take a look at different ways of assessing popularity of repositories. The results show that regardless of the metrics, the popular repositories are popular – i.e. popularity is not dependent of a metric.
Popularity metrics studied:
- Total number of downloads of the package
- Number of projects dependent on the package
- Number of repositories dependent on the package
- Source rank of the package
- Number of forks
- Number of watchers
- Number of contributors
- Number of stars
- Number of open issues
- Total number of tags
The actual analysis is quite interesting, so I recommend to take a look at the paper directly.