Our Software Center project has worked with a number of companies to increase the impact of KPIs in modern organizations. Although the concept of KPI has been around since the 90s, many organizations still struggle with making KPIs actionable.
In this post, I’ll show the results of one of the recent assessments of KPIs. To get the understanding of how the KPIs are worked, I’ve asked about 20 managers to assess some of the KPIs used in their organizations. We used a simplified model of KPI quality, developed in the last spring. The results are presented in the figure below.
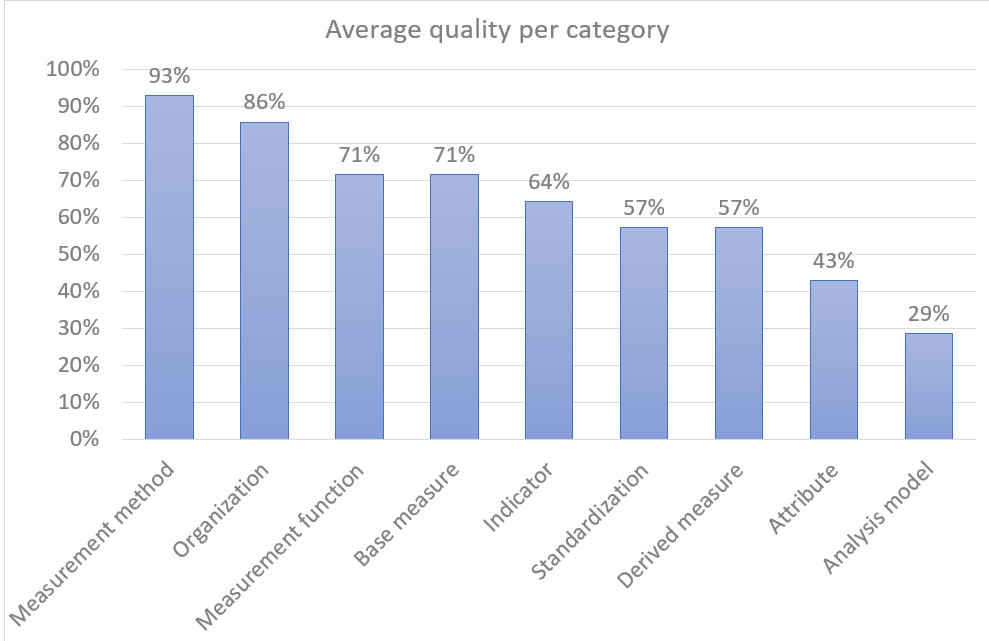
The figure shows what the gut feeling would tell us – that the major quality problems with the KPIs is the lack of clear guidelines how to react. The company has no problem with the mathematics, the quantification or even the presentation. The major challenge is the analysis model and the action model linked to that.
How to change this situation?
1. Create an action plan – what to check when the indicator shows red?
2. Find the stakeholder who has the right mandate to act.
3. Make sure that the stakeholder checks the status of the indicator regularly.
4. Make sure that the indicator stays updated and maintained.
If the above cannot be fulfilled, then it makes no sense to have the KPI, remove it, forget it and move forward with another business goal.
To read more how we assess KPI’s quality, take a look at this paper:
Staron, Miroslaw, Wilhelm Meding, Kent Niesel, and Alain Abran. “A Key performance indicator quality model and its industrial evaluation.” In Software Measurement and the International Conference on Software Process and Product Measurement (IWSM-MENSURA), 2016 Joint Conference of the International Workshop on, pp. 170-179. IEEE, 2016.
Link: https://ieeexplore.ieee.org/abstract/document/7809605/

