In the eve of 2019, I got the time to read my copy of AI Superpowers. I must admit that I was sceptical towards it in the beginning. I’ve read a fair number of AI books and many of them were quite superficial – a lot of text, but not much novelty. However, this book seemed to be different.
First of all, the book is about the innovators and the transformations from low-tech to high-tech. The transformation is described as a process of learning. First copying the solution of others, then making your own. First learning the market, then creating your own. Finally, the examples of building the software start-up ecosystem are based on these small examples.
Second of all, the book discusses the issues that I’ve advocated for since a while back – the ability to utilise the data at hand. The European GDPR is a great tool for us, but it can stop the innovation. China’s lack of GDPR is a problem, but also a possibility. However, it needs to be tackled or it will never be fair. the description of the wars between companies show that the scene in China is not like it is in the Silicon Valley. It’s not great, but it was a mystery to me before. I’ve not really reflected upon that.
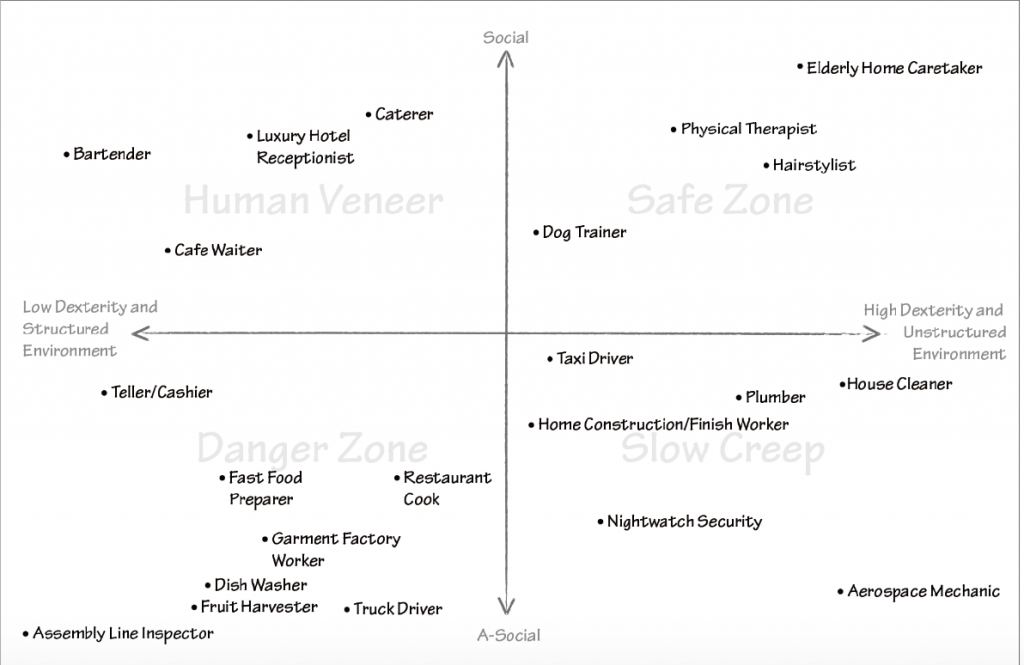
I guess that looking at the holistic picture of how Ai will affect the society is not very common. Well, maybe except the doomsday prophecies about how AI will take our jobs. This book is a bit difference in that respect. It looks at the need for basic income and how this could reshape the society. It discusses how this can be done both on the technical and on the social levels. To show a preview of it, please take a look at how the Kai-Lee predicts that the AI will affect our work.
Finally, I’ve got a number of ideas from the book. Ideas which I can use in the upcoming course about start-ups. I strongly recommend the book to my students and all entrepreneurs, who want to understand the possibilities of this new technology. I also recommend this book for people who believe in doomsday prophecies about AI – the revolution is near, but AI will not be like a Terminator. More like HAL 🙂